Incremental Updates
Hadoop and Hive are quickly evolving to outgrow previous limitations for integration and data access.
On the near-term development roadmap, we expect to see Hive supporting full CRUD operations (Insert, Select, Update, Delete). As we wait for these advancements, there is still a need to work with the current options—OVERWRITE or APPEND— for Hive table integration.
On the near-term development roadmap, we expect to see Hive supporting full CRUD operations (Insert, Select, Update, Delete). As we wait for these advancements, there is still a need to work with the current options—OVERWRITE or APPEND— for Hive table integration.
The OVERWRITE option requires moving the complete record set from source to Hadoop. While this approach may work for smaller data sets, it may be prohibitive at scale.
The APPEND option can limit data movement only to new or updated records. As true Inserts and Updates are not yet available in Hive, we need to consider a process of preventing duplicate records as Updates are appended to the cumulative record set.
In this blog, we will look at a four-step strategy for appending Updates and Inserts from delimited and RDBMS sources to existing Hive table definitions. While there are several options within the Hadoop platform for achieving this goal, our focus will be on a process that uses standard SQL within the Hive toolset.
IMPORTANT: For this blog, we assume that each source table will have a unique single or multi-key identifier and that a “modified_date” field is maintained for each record – either defined as part of the original source table or added as part of the ingest process.
Hive Table Definition Options: External, Local and View
External Tables are the combination of Hive table definitions and HDFS managed folders and files. The table definition exists independent from the data, so that, if the table is dropped, the HDFS folders and files remain in their original state.
Local Tables are Hive tables that are directly tied to the source data. The data is physically tied to the table definition and will be deleted if the table is dropped.
Views, as with traditional RDBMS, are stored SQL queries that support the same READ interaction as HIVE tables, yet they do not store any data of their own. Instead, the data are stored and sourced from the HIVE tables referenced in the stored SQL query.
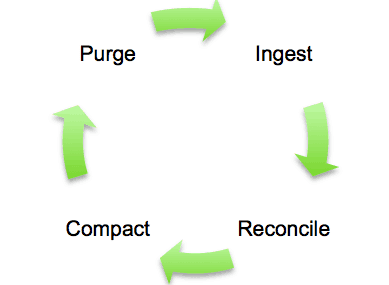
The following process outlines a workflow that leverages all of the above in four steps:
 |
|
The tables and views that will be a part of the Incremental Update Workflow are:
|
Step 1: Ingest
Depending on whether direct access is available to the RDBMS source system, you may opt for either a File Processing method (when no direct access is available) or RDBMS Processing (when database client access is available).
Regardless of the ingest option, the processing workflow in this article requires:
- One-time, initial load to move all data from source table to HIVE.
- On-going, “Change Only” data loads from the source table to HIVE.
Below, both File Processing and Database-direct (SQOOP) ingest will be discussed.
File Processing
For this blog, we assume that a file or set of files within a folder will have a delimited format and will have been generated from a relational system (i.e. records have unique keys or identifiers).
Files will need to be moved into HDFS using standard ingest options:
- WebHDFS: Primarily used when integrating with applications, a Web URL provides an Upload end-point into a designated HDFS folder.
- NFS: Appears as a standard network drive and allows end-users to use standard Copy-Paste operations to move files from standard file systems into HDFS.
Once the initial set of records are moved into HDFS, subsequent scheduled events can move files containing only new Inserts and Updates.
RDBMS Processing
SQOOP is the JDBC-based utility for integrating with traditional databases. A SQOOP Import allows for the movement of data into either HDFS (a delimited format can be defined as part of the Import definition) or directly into a Hive table.
The entire source table can be moved into HDFS or Hive using the “–table” parameter
sqoop import --connect jdbc:teradata://{host name or ip address}/Database=retail --connection-manager org.apache.sqoop.teradata.TeradataConnManager --username dbc --password dbc --table SOURCE_TBL --target-dir /user/hive/incremental_table -m 1
After the initial import, subsequent imports can leverage SQOOP’s native support for “Incremental Import” by using the “check-column”, “incremental” and “last-value” parameters.
sqoop import --connect jdbc:teradata://{host name or ip address}/Database=retail --connection-manager org.apache.sqoop.teradata.TeradataConnManager --username dbc --password dbc --table SOURCE_TBL --target-dir /user/hive/incremental_table -m 1--check-column modified_date --incremental lastmodified --last-value {last_import_date}
Alternately, you can leverage the “query” parameter, and have SQL select statements limit the import to new or changed records only.
sqoop import --connect jdbc:teradata://{host name or ip address}/Database=retail --connection-manager org.apache.sqoop.teradata.TeradataConnManager --username dbc --password dbc --target-dir /user/hive/incremental_table -m 1 --query 'select * from SOURCE_TBL where modified_date > {last_import_date} AND $CONDITIONS’
Note: For the initial load, substitute “base_table” for “incremental_table”. For all subsequent loads, use “incremental_table”.
Step 2: Reconcile
In order to support an on-going reconciliation between current records in HIVE and new change records, two tables should be defined: base_table and incremental_table
base_table
The example below shows DDL for the Hive table “base_table” that will include any delimited files located in HDFS under the ‘/user/hive/base_table’ directory. This table will house the initial, complete record load from the source system. After the first processing run, it will house the on-going, most up-to-date set of records from the source system:
01
02
03
04
05
06
07
08
09
10
11
12
| CREATE TABLE base_table ( id string, field1 string, field2 string, field3 string, field4 string, field5 string, modified_date string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','LOCATION '/user/hive/base_table'; |
incremental_table
The DDL below shows an external Hive table “incremental_table” that will include any delimited files with incremental change records, located in HDFS under the ‘/user/hive/incremental_append’ directory:
01
02
03
04
05
06
07
08
09
10
11
12
| CREATE EXTERNAL TABLE incremental_table ( id string, field1 string, field2 string, field3 string, field4 string, field5 string, modified_date string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','LOCATION '/user/hive/incremental_table'; |
reconcile_view
This view combines record sets from both the Base (base_table) and Change (incremental_table) tables and is reduced only to the most recent records for each unique “id”.
It is defined as follows:
It is defined as follows:
01
02
03
04
05
06
07
08
09
10
11
12
| CREATE VIEW reconcile_view ASSELECT t1.* FROM(SELECT * FROM base_table UNION ALL SELECT * FROM incremental_table) t1JOIN (SELECT id, max(modified_date) max_modified FROM (SELECT * FROM base_table UNION ALL SELECT * FROM incremental_table) t2 GROUP BY id) s ON t1.id = s.id AND t1.modified_date = s.max_modified; |
Example
The sample data below represents the UNION of both the base_table and incremental_table. Note, there are new updates for “id” values 1 and 2, which are found as the last two records in the table. The record for “id” 3 remains unchanged.
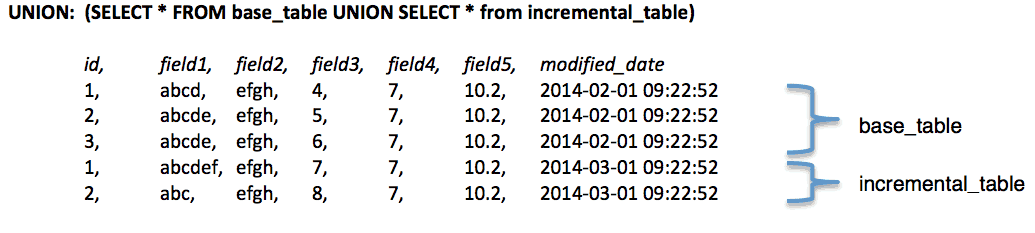
The reconcile_view should only show one record for each unique “id”, based on the latest “modified_date” field value.
The resulting query from “select * from reconcile_view” shows only three records, based on both unique “id” and “modified_date”
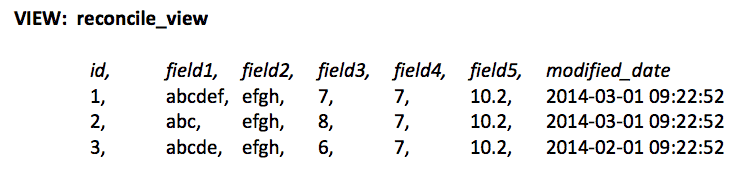
Step 3: Compact
The reconcile_view now contains the most up-to-date set of records and is now synchronized with changes from the RDBMS source system. For BI Reporting and Analytical tools, a reporting_table can be generated from the reconcile_view. Before creating this table, any previous instances of the table should be dropped as in the example below.
reporting_table
1
2
3
| DROP TABLE reporting_table;CREATE TABLE reporting_table ASSELECT * FROM reconcile_view; |
Moving the Reconciled View (reconcile_view) to a Reporting Table (reporting_table) reduces the amount of processing needed for reporting queries.
Further, the data stored in the Reporting Table will also be static, unchanged until the next processing cycle. This provides consistency in reporting between processing cycles. In contrast, the Reconciled View (reconcile_view) is dynamic and will change as soon as new files (holding change records) are added to or removed from the Change table (incremental_table) folder /user/hive/incremental_table.
Step 4: Purge
To prepare for the next series of incremental records from the source, replace the Base table (base_table) with only the most up-to-date records (reporting_table). Also, delete the previously imported Change record content (incremental_table) by deleting the files located in the external table location (‘/user/hive/incremental_table’).
From a HIVE client:
1
2
3
| DROP TABLE base_table;CREATE TABLE base_table ASSELECT * FROM reporting_table; |
From an HDFS client:
hadoop fs –rm –r /user/hive/incremental_table/*Final Thoughts
While there are several possible approaches to supporting incremental data feeds into Hive, this example has a few key advantages:
- By maintaining an External Table for updates only, the table contents can be refreshed by simply adding or deleting files to that folder.
- The four steps in the processing cycle (Ingest, Reconcile, Compact and Purge) can be coordinated in a single OOZIE workflow. The OOZIE workflow can be a scheduled event that corresponds to the data freshness SLA (i.e. Daily, Weekly, Monthly, etc.)
- In addition to supporting INSERT and UPDATE synchronization, DELETES can be synchronized by adding either a DELETE_FLAG or DELETE_DATE field to the import source. Then, use this field as a filter in the Hive reporting table to hide deleted records. For example,01020304050607080910111213
CREATEVIEWreconcile_viewASSELECTt1.*FROM(SELECT*FROMbase_tableUNIONSELECT*FROMincremental_table) t1JOIN(SELECTid,max(modified_date) max_modifiedFROM(SELECT*FROMbase_tableUNIONSELECT*FROMincremental_table)GROUPBYid) sONt1.id = s.idANDt1.modified_date = s.max_modifiedANDt1.delete_dateISNULL;
In essence, this four-step strategy enables incremental updates, as we await the near-term development
of Hive support for full CRUD operations (Insert, Select, Update, Delete).
of Hive support for full CRUD operations (Insert, Select, Update, Delete).
Please elaborate Delete Design
ReplyDeletemardin
ReplyDeleteerzincan
kars
antep
çorum
X65H4Z